GPT 变得好用了,但真的更聪明了吗?
昨天,很多人彻夜未眠 —— 全球科技圈都把目光聚焦在了美国旧金山。
短短 45 分钟时间里,OpenAI CEO 山姆・奥特曼向我们介绍了迄今为止最强的大模型,和基于它的一系列应用,一切似乎就像当初 ChatGPT 一样令人震撼。

OpenAI 在本周一的首个开发者日上推出了 GPT-4 Turbo,新的大模型更聪明,文本处理上限更高,价格也更便宜,应用商店也开了起来。现在,用户还可以根据需求构建自己的 GPT。
根据官方说法,这一波 GPT 的升级包括:
更长的上下文长度:128k,相当于 300 页文本。
更高的智能程度,更好的 JSON / 函数调用。
更高的速度:每分钟两倍 token。
知识更新:目前的截止日期为 2023 年 4 月。
定制化:GPT3 16k、GPT4 微调、定制模型服务。
多模态:Dall-E 3、GPT4-V 和 TTS 模型现已在 API 中。
Whisper V3 开源(即将推出 API)。
与开发者分享收益的 Agent 商店。
GPT4 Turbo 的价格约是 GPT4 的 1/3。
发布会一开完,人们蜂拥而入开始尝试。GPT4 Turbo 的体验果然不同凡响。首先是快,快到和以前所有大模型拉开了代差:
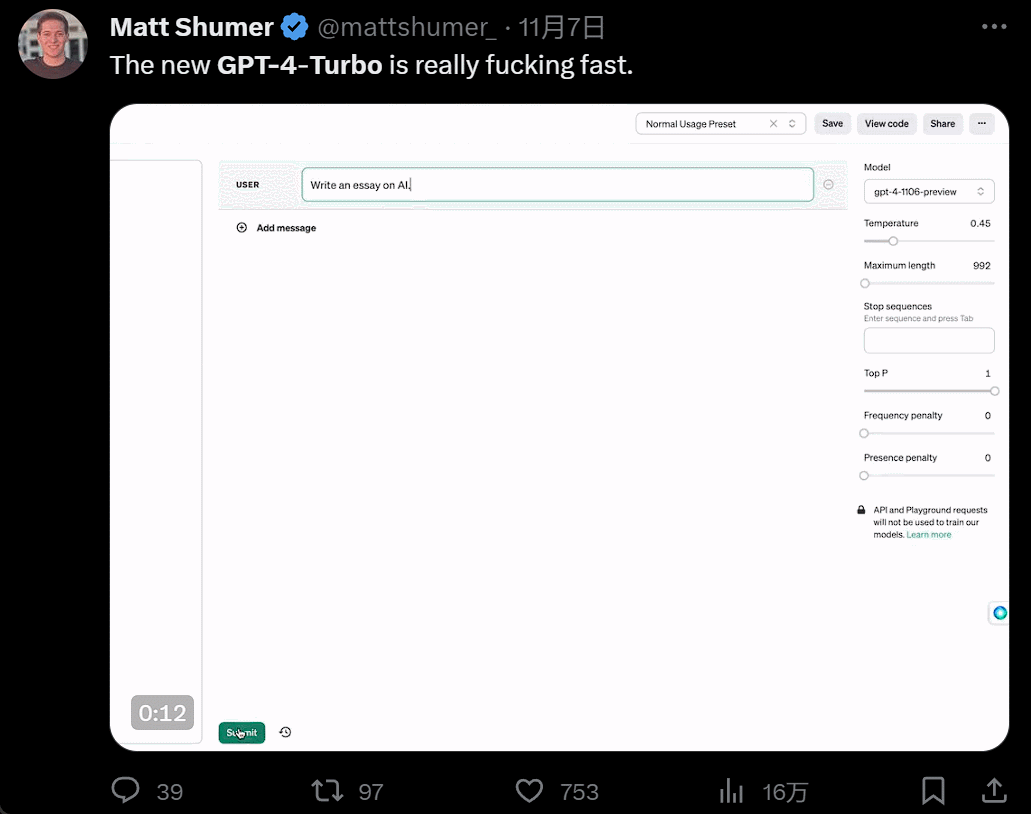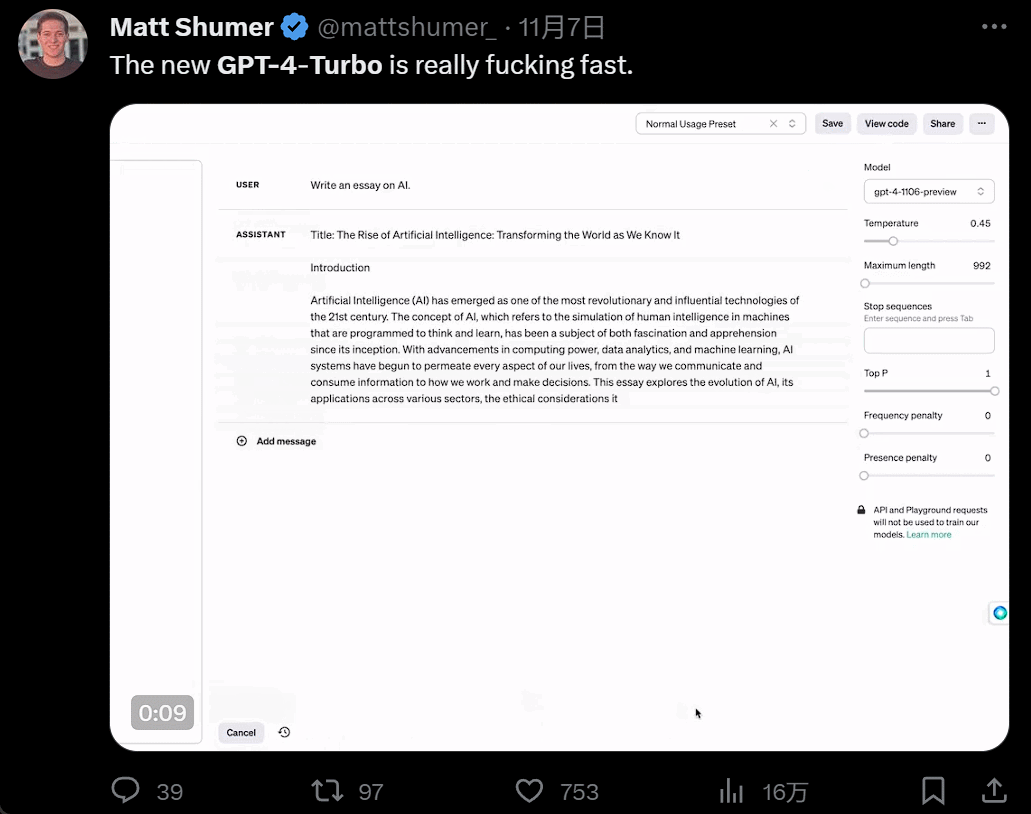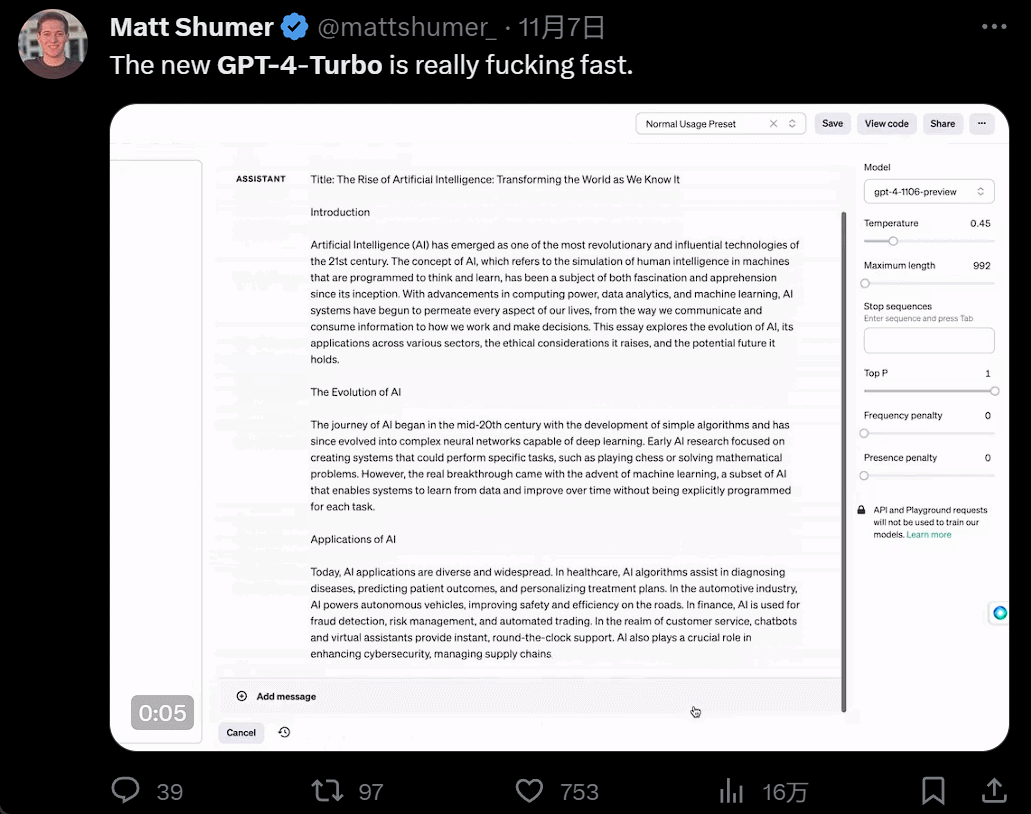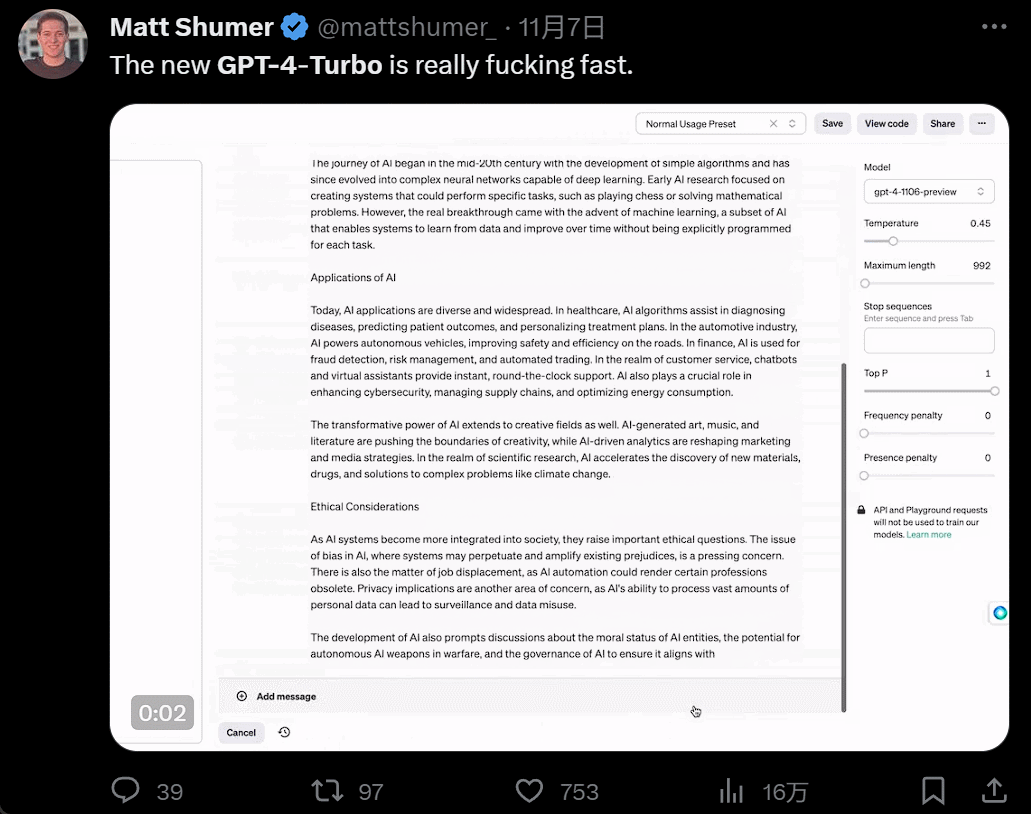
然后是功能增多,画画的时候,你一有灵感就可以直接说话让 AI 负责实现:

设计个 UI,几个小时的工作变成几分钟:

我直接不装了,截个图复制粘贴别人的网站,生成自己的,只用 40 秒:
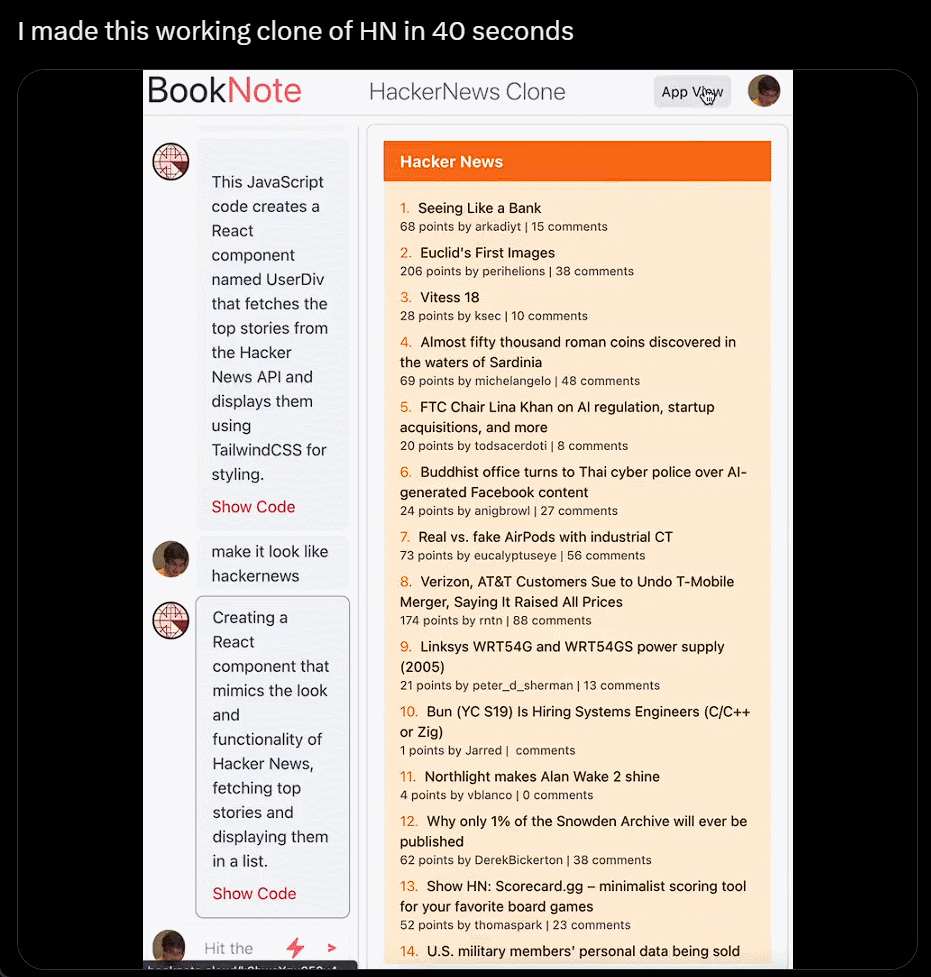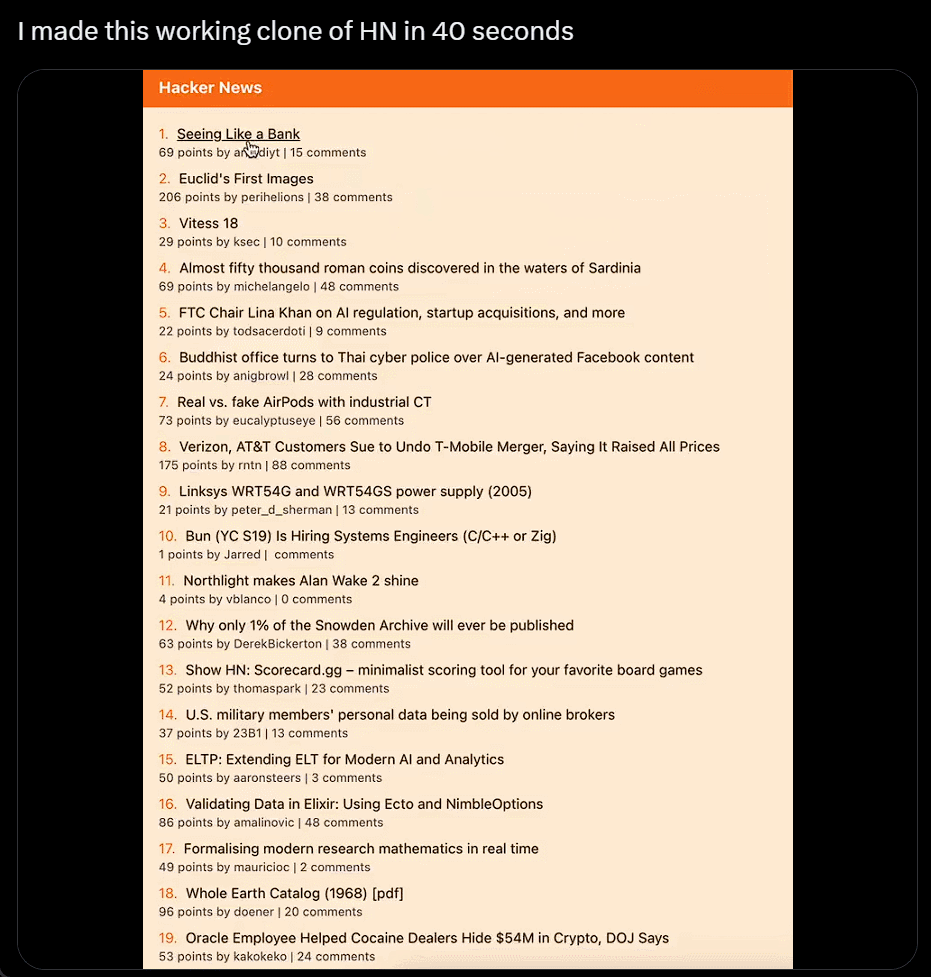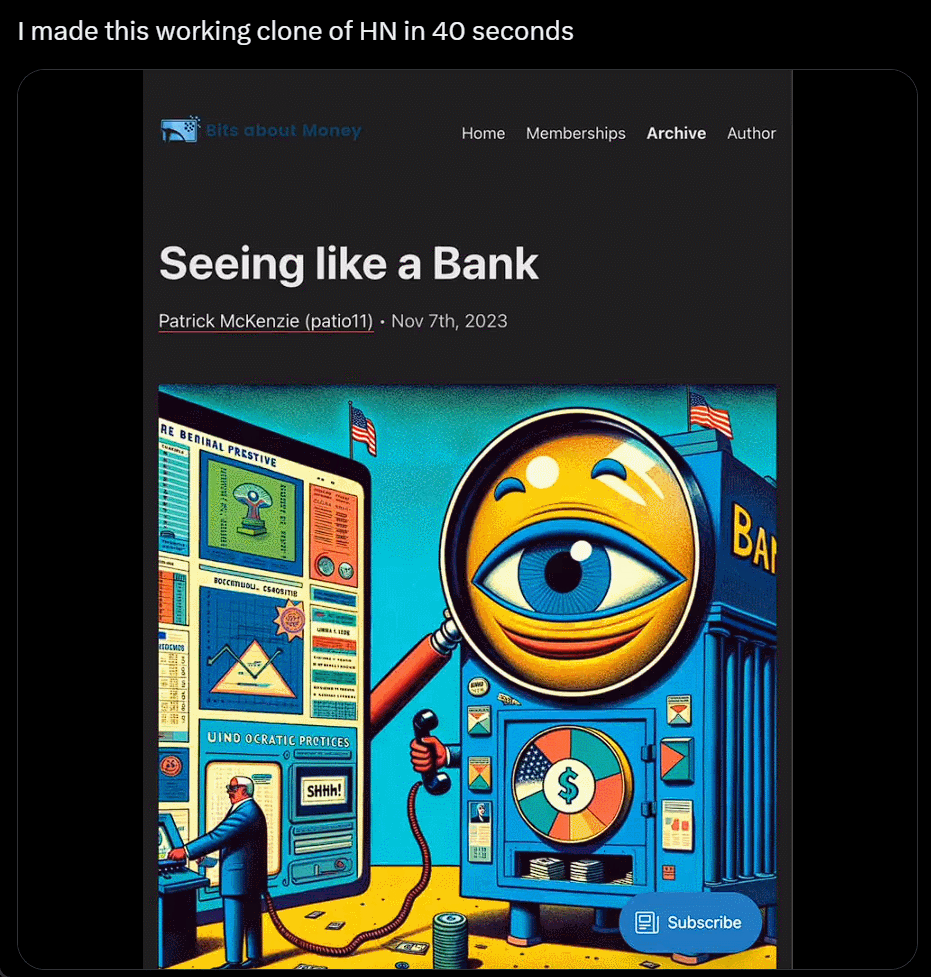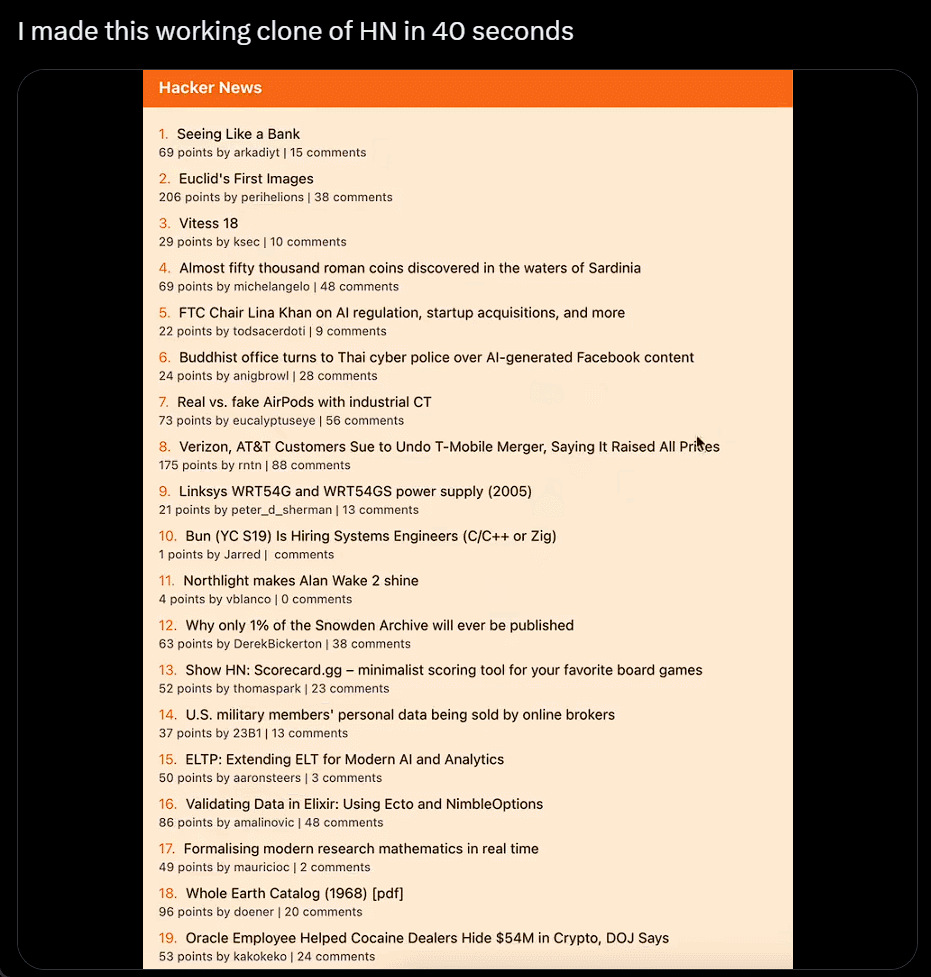
利用 ChatGPT 与 Bing 的浏览功能以及与 DALL-E 3 图像生成器的集成,沃顿商学院教授 Ethan Mollick 分享了一段视频,展示了他的名为「趋势分析器」的 GPT 工具,其可查找市场特定细分市场的趋势,然后创建新产品的原型图像。
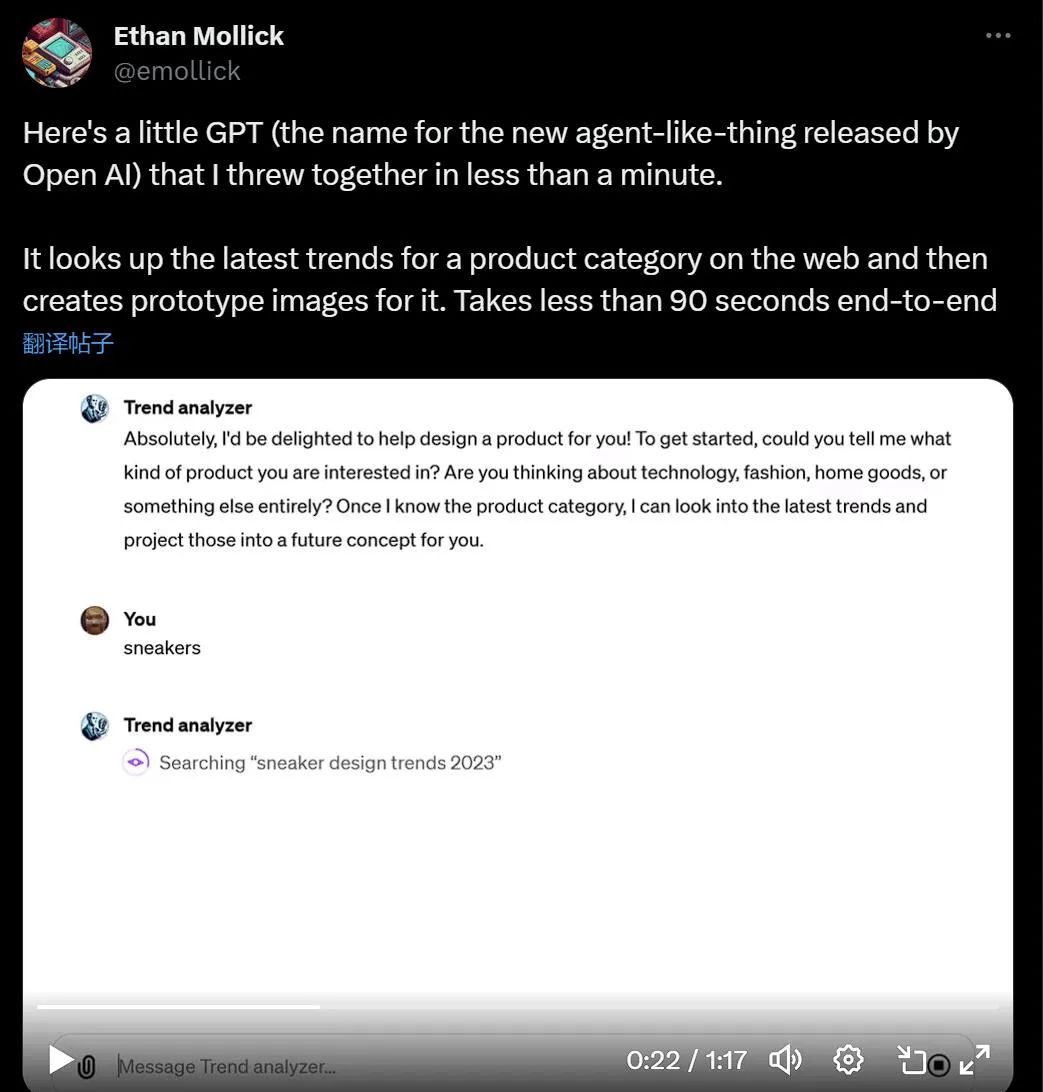
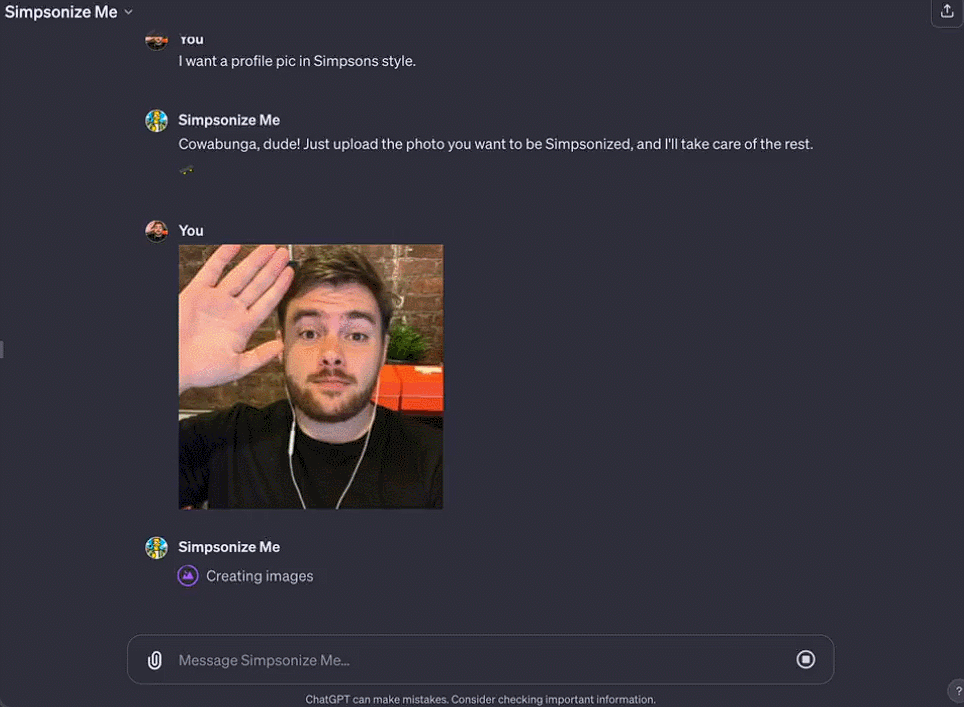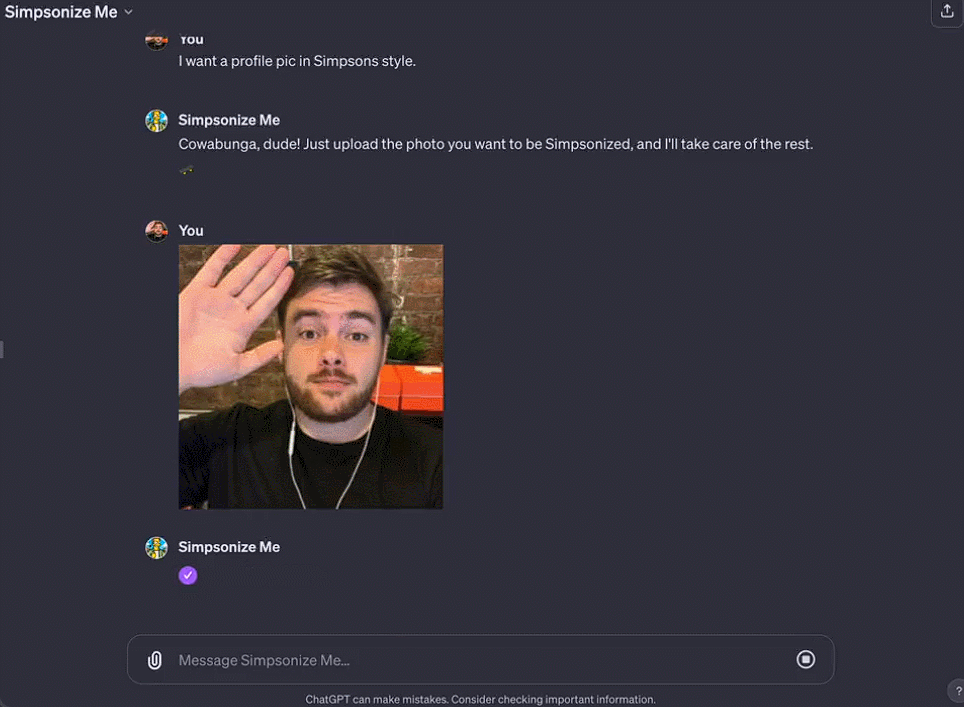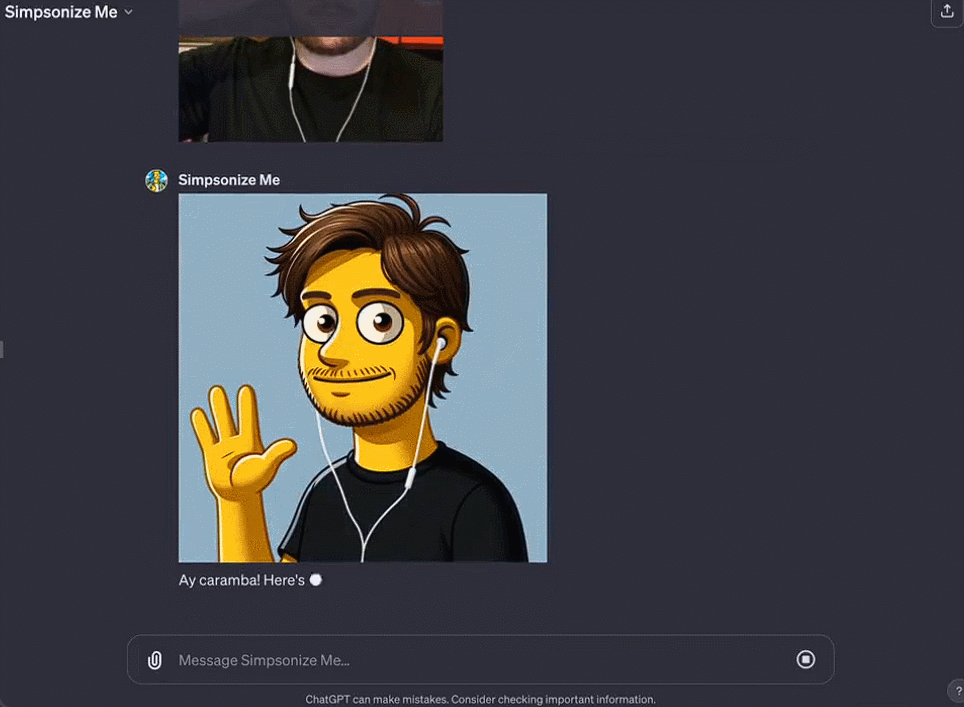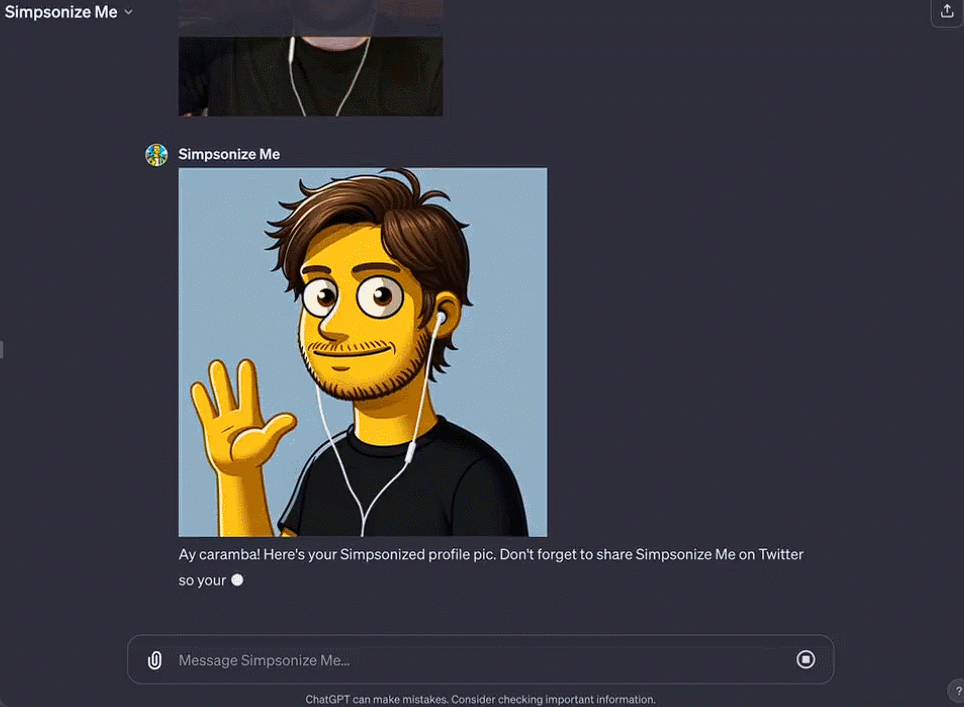
Octane AI 首席执行官 Matt Schlicht 的 Simponize Me GPT 会自动应用提示来转换用户上传的个人资料照片,生成《辛普森一家》的风格,做这个小应用只用了不到十分钟。
GPT-4 Turbo 具有创纪录的准确率,在 PyLLM 基准上,GPT-4 Turbo 的准确率是 87%,而 GPT-4 的准确率是 52%,这是在速度几乎快了四倍多的情况下(每秒 48 token)实现的。
至此,生成式 AI 的竞争似乎进入了新的阶段。很多人认为,当竞争对手们依然在追求更快、能力更强的大模型时,OpenAI 其实早就已经把所有方向都试过了一遍,这一波更新会让一大批创业公司作古。

也有人表示,既然 Agent 是大模型重要的方向,OpenAI 也开出了 Agent 应用商店,接下来在智能体领域,我们会有很多机会。
竞争者们真的无路可走了吗?价格降低,速度变快以后,大模型的性能还能同时变得更好?这必须要看实践,在 OpenAI 的博客中,其实说法是这样的:在某些格式的输出下,GPT-4 Turbo 会比 GPT-4 结果更好。那么总体情况会如何?
在新模型发布的 24 小时内,就有研究者在 Aider 上进行了 AI 生成代码的能力测试。
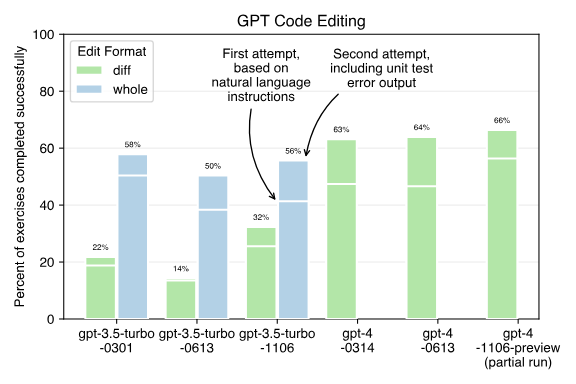
在 gpt-4-1106-preview 模型上,仅使用 diff 编辑方法对 GPT-4 模型进行基准测试得出的结论是:
新的 gpt-4-1106-preview 模型似乎比早期的 GPT-4 模型快得多;
第一次尝试时似乎更能生成正确的代码,能正确完成大约 57% 的练习,以前的模型在第一次尝试时只能正确完成 46-47% 的练习;
在通过检查测试套件错误输出获得第二次纠正错误的机会后,新模型的表现 (~66%) 似乎与旧模型 (63-64%) 相似 。
接下来是使用 whole 和 diff 编辑格式对 GPT-3.5 模型进行的基准测试。结果表明,似乎没有一个 gpt-3.5 模型能够有效地使用 diff 编辑格式,包括最新的 11 月出现的新模型( 简称 1106)。下面是一些 whole 编辑格式结果:
新的 gpt-3.5-turbo-1106 型号完成基准测试的速度比早期的 GPT-3.5 型号快 3-4 倍;
首次尝试后的成功率为 42%,与之前的 6 月 (0613) 型号相当。1106 模型和 0613 模型都比原来的 0301 第一次尝试的结果更差,为 50%;
新模型在第二次尝试后的成功率为 56%,似乎与 3 月的模型相当,但比 6 月的模型要好一些,6 月的模型为 50% 得分。
这项测试是如何进行的呢,具体而言,研究者让 Aider 尝试完成 133 个 Exercism Python 编码练习。对于每个练习,Exercism 都提供了一个起始 Python 文件,文件包含所要解决问题的自然语言描述以及用于评估编码器是否正确解决问题的测试套件。
基准测试分为两步:
第一次尝试时,Aider 向 GPT 提供要编辑的桩代码文件以及描述问题的自然语言指令。这些指令反映了用户如何使用 Aider 进行编码。用户将源代码文件添加到聊天中并请求更改,这些更改会被自动应用。
如果测试套件在第一次尝试后失败,Aider 会将测试错误输出提供给 GPT,并要求其修复代码。Aider 的这种交互式方式非常便捷,用户使用 /run pytest 之类的命令来运行 pytest 并在与 GPT 的聊天中共享结果。
然后就有了上述结果。至于 Aider ,对于那些不了解的小伙伴,接下来我们简单介绍一下。
Aider 是一个命令行工具,可以让用户将程序与 GPT-3.5/GPT-4 配对,以编辑本地 git 存储库中存储的代码。用户既可以启动新项目,也可以使用现有存储库。Aider 能够确保 GPT 中编辑的内容通过合理的提交消息提交到 git。Aider 的独特之处在于它可以很好地与现有的更大的代码库配合使用。
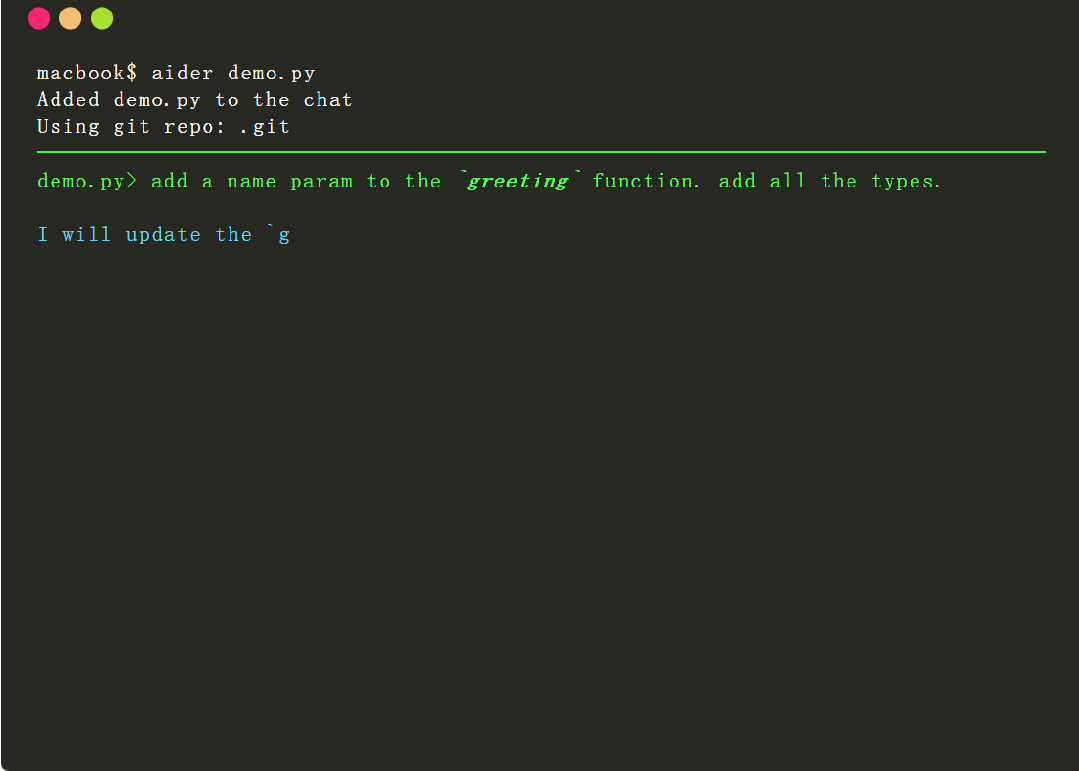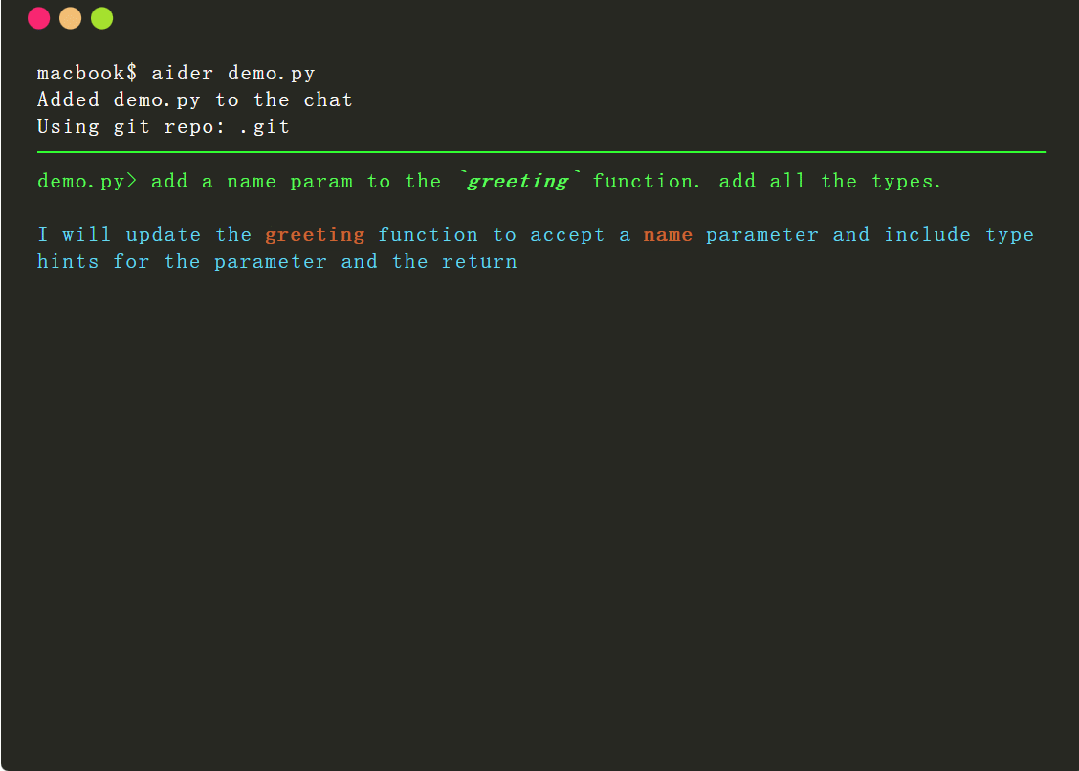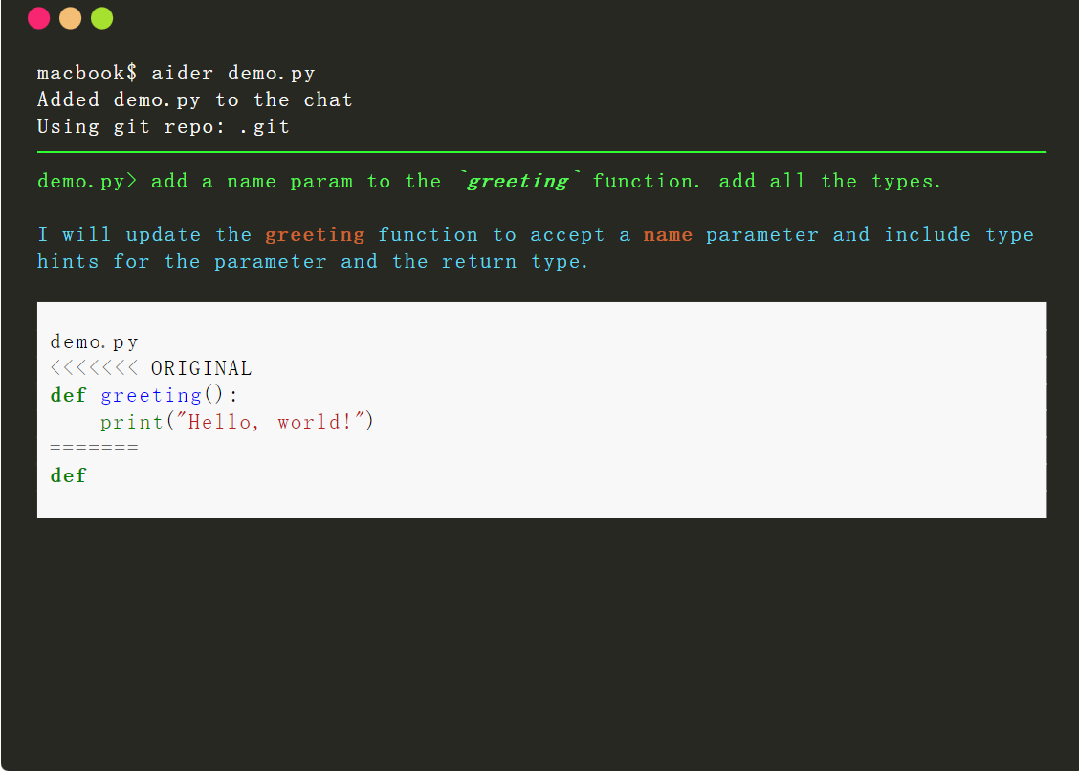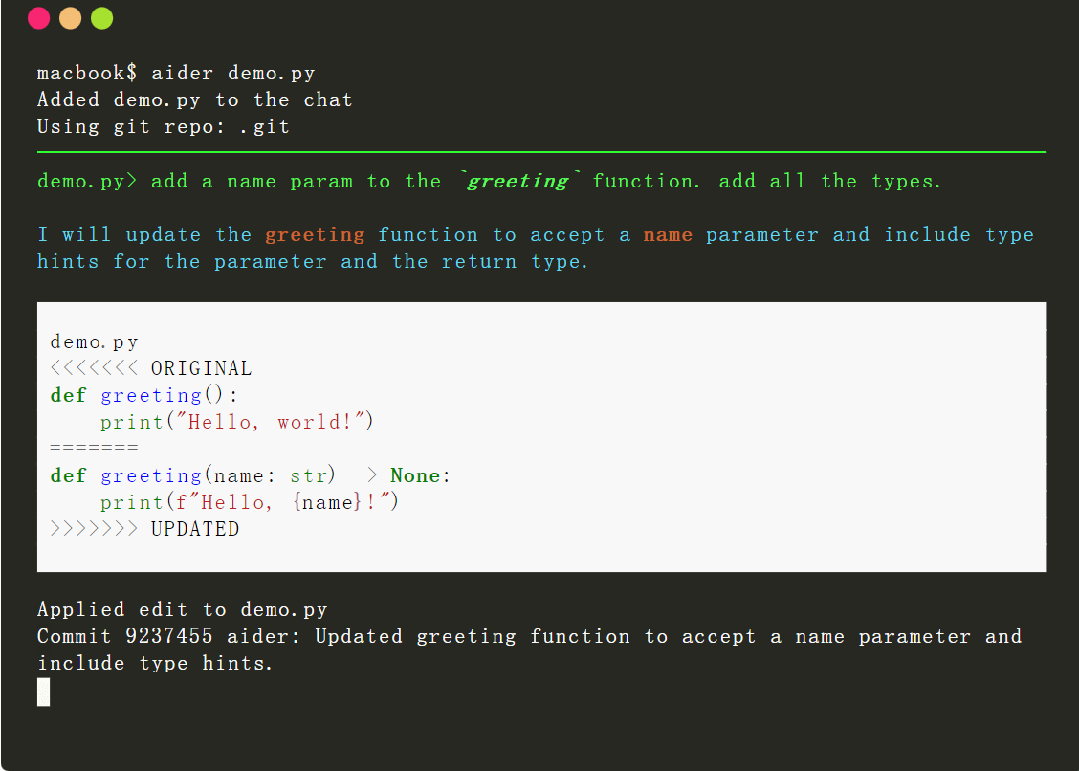
简单总结就是,借助该工具,用户可以使用 OpenAI 的 GPT 编写和编辑代码,轻松地进行 git commit、diff 和撤消 GPT 提出的更改,而无需复制 / 粘贴,它还具有帮助 GPT-4 理解和修改更大代码库的功能。
为了达到上述功能,Aider 需要能够准确地识别 GPT 何时想要编辑用户源代码,还需要确定 GPT 想要修改哪些文件并对 GPT 做出的修改进行准确的应用。然而,做好这项「代码编辑」任务并不简单,需要功能较强的 LLM、准确的提示以及与 LLM 交互的良好工具。
操作过程中,当有修改发生时,Aider 会依靠代码编辑基准(code editing benchmark)来定量评估修改后的性能。例如,当用户更改 Aider 的提示或驱动 LLM 对话的后端时,可以通过运行基准测试以确定这些更改产生多少改进。
此外还有人使用 GPT-4 Turbo 简单和其他模型对比了一下美国高考 SAT 的成绩:
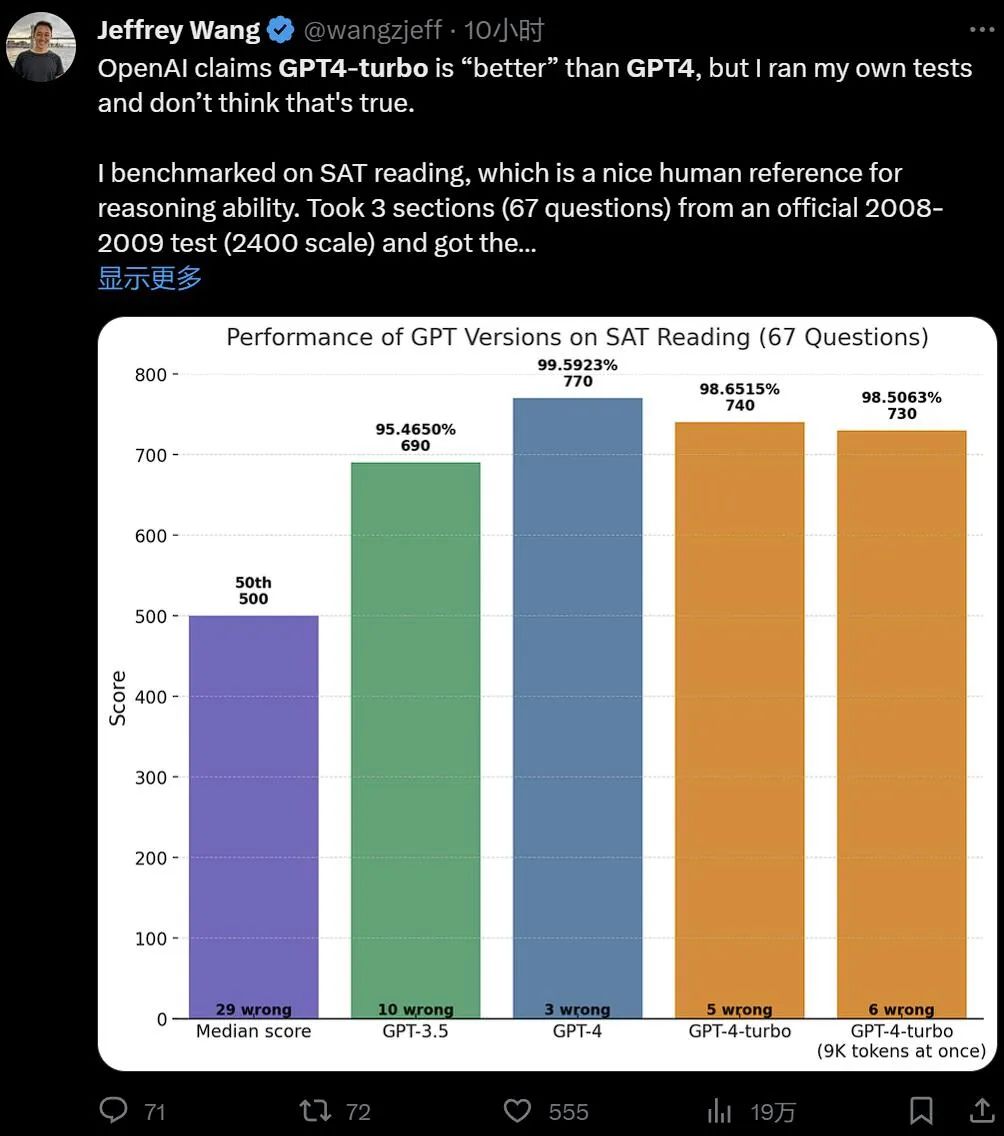
同样,看起来聪明的程度并没有拉开代差,甚至还有点退步。不过必须要指出的是,实验的样本数量很小。
综上所述,GPT-4 Turbo 的这一波更新更重要的是完善了功能,增加了速度,准确性是否提高仍然存疑。这或许与整个大模型业界目前的潮流一致:重视优化,面向应用。业务落地速度慢的公司要小心了。
另一方面,从这次开发者日的发布内容来看,OpenAI 也从一个极度追求前沿技术的创业公司,变得开始关注起用户体验和生态构建,更像大型科技公司了。
再次颠覆 AI 领域的 GPT-5,我们还得再等一等。
参考内容:
https://venturebeat.com/ai/what-can-you-make-with-openais-gpt-builder-5-early-examples/
https://aider.chat/docs/benchmarks-1106.html
https://weibo.com/2194035935/N8pSZCdxH
AI

 新浪科技公众号
新浪科技公众号 “掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)
 相关新闻
相关新闻 